前言
今天总结一个小知识点,虽然不难,但是对新手有很强的迷惑性,了解一下也挺好。我们在使用 Git 回退到版本的时候,可能见过这种写法 git reset --hard HEAD~,有时候也会遇到这种写法 git reset --hard HEAD^,这两个语句都是将代码库还原到上一个版本,但是只差了一个符号,他们究竟有什么区别呢?这里先给出结论:HEAD~ 和 HEAD^ 含义不同,功能一样!
HEAD
HEAD 这个词在 git 使用过程中经常出现,作用很像是数据结构中指向二叉树根节点root的指针。有个 root 指针我们就可以对二叉树进行任意操作,它是二叉树的根基。而 git 中的 HEAD 概念也类似一个指针,它指向是当前分支的“头”,通过这个头节点可以追寻到当前分支之前的所有提交记录。
git 的提交记录之间的关系很像一棵树,或者说是一张图,通过当前的提交记录指向上一次提交记录串联起来,形成一个头结构,而在 git 中我们常常说的切换分支,只不过是 git 客户端帮你把要操作的那条路径的头节点,存储到了 HEAD 文件中。
HEAD 在 git 版本控制中代表头节点,也就是分支的最后一次提交,同时也是一个文件,通常在版本库中 repository/.git/HEAD,其中保存的一般是 ref: refs/heads/master 这种分支的名字,而本质上就是指向一次提交的 hash 值,一般长成这个样子 ce11d9be5cc7007995b607fb12285a43cd03154b。
HEAD~ 和 HEAD^
在 HEAD 后面加 ^ 或者 ~ 其实就是以 HEAD 为基准,来表示之前的版本,因为 HEAD 被认为是当前分支的最新版本,那么 HEAD~ 和 HEAD^ 都是指次新版本,也就是倒数第二个版本,HEAD~~ 和 HEAD^^ 都是指次次新版本,也就是倒数第三个版本,以此类推。
这个说法在之前的总结 《git checkout/git reset/git revert/git restore常用回退操作》 中提到过,但是并未展开说,今天就来测试一下。
HEAD 后面 ~ 和 ^ 的区别
其实 HEAD~ 和 HEAD^ 的作用是相同的,这两者的区别出现在重复使用或者加数字的情况,下面来分情况说明一下。
HEAD~ 和 HEAD^后面都加1
加上参数1之后变成了 HEAD~1 和 HEAD^1,其实这就是他们本来的面貌,在参数为 1 的情况下可以省略,HEAD~1 表示回退一步,参数1表示后退的步数,默认推到第一个父提交上,而HEAD^1表示后退一步,直接后退到第n个父提交上,数字1表示是第一个父提交。
这里引入一个父提交的概念,也就是在最新提交之前的最近的提交我称它为父提交,但是父提交会有两个吗?实际上会的,直接的父提交可能会有很多,分支合并是产生父提交的一种常见原因,两个分支合并到一起时,这两个分支的原 HEAD 都会成为合并后最新提交的父提交。
理解了这个概念,我们发现虽然数字是一样的,但是含义却不相同,HEAD~1 中指的是后退的步数,HEAD^1指的是退到第几个父提交上。
HEAD~ 和 HEAD^后面都加0
这是一种比较特殊的情况, 加上参数0之后变成了 HEAD~0 和 HEAD^0,其实他们指向的节点没有改变,还是代表了 HEAD,只要了解这种情况就行了,我还没有见过谁这样写过。
HEAD~ 和 HEAD^后面都加大于1的数字
这时就会发现两者的不同了,比如我们把数字都定为2,那么 HEAD~2 代表后退两步,每一步都后退到第一个父提交上,而 HEAD^2 代表后退一步,这一步退到第二个父提交上,如果没有第二个父提交就会报出以下错误:
fatal: ambiguous argument ‘HEAD^2’: unknown revision or path not in the working tree.
Use ‘–’ to separate paths from revisions, like this:
‘git[ …] – [ …]’
具体示例
上面说了几种加数字的情况,如果是第一次接触可能还是不太明白,没关系,我可以实际操作一下,看个具体的例子就明白了。
准备工作
下面是一个测试代码库的分支结构,一共有 dev1、dev2、dev3、dev4 四个分支,最终合并到 dev1 分支,提交记录如下:
1 | albert@home-pc MINGW64 /d/gitstart (dev1) |
也许有颜色标记会看得更清楚一些,所以截个图放在这:
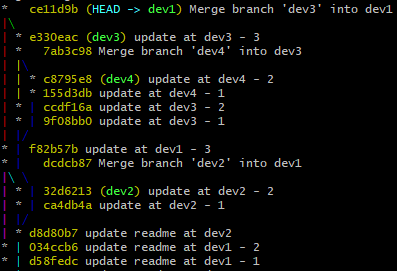
刚看这种图的时候要注意一点,记录列表中的先后关系不代表提交时间的先后,如果习惯于看SVN的记录以后,很容易在看日志信息时加上时间因素,但是这个时间因素在 git 查看记录时变得不再明显,比如上面记录中的 e330eac 在图形上要比 f82b57b 更接近 HEAD 提交 ce11d9b,但是因为处在不同的分支上,在合并之前他俩的修改时间还真不一定是哪个更早一些。
树形记录
在 git 的提交记录图上,我们可以确定当前提交的父提交(所依赖的提交)是哪一个或者哪几个,但是不能确定任意两个提交的时间先后,为了能更清楚的看清分支提交的依赖关系,还是看下面这个树形图更方便一些。
1 | graph TB |
查看命令
在验证 HEAD~ 和 HEAD^ 之前我们先学习一个命令 git rev-parse HEAD 这个命令可以显示出 HEAD 对应的提交的 hash 值,加上 --short 参数就可以显示出长度为7位的短 hash,用起来比较方便,测试如下:
1 | albert@home-pc MINGW64 /d/gitstart (dev1) |
开始测试
下面可以用 git rev-parse --short 命令来测试 HEAD 后面跟不同参数时对应的提交是哪一个了,测试如下:
HEAD~、HEAD^、HEAD~1、HEAD^1
1 | albert@home-pc MINGW64 /d/gitstart (dev1) |
测试后发现,这四种写法结果是一样的,都是指向 HEAD 的第一个父提交,这和我们前面说的观点一致。
HEAD~~、HEAD^^、HEAD~2、HEAD^2
1 | albert@home-pc MINGW64 /d/gitstart (dev1) |
这次我们发现,前三个表示方法是一样的,指向同一个提交记录,但是最后一个与他们不同,这时根据前面提到定义来看就行了,HEAD~~ 实际上是 HEAD~1~1的简写,而~ 后的数字就是指的后退的步数,所以 HEAD~~ 等价于 HEAD~2,属于一种合并计算。
HEAD^^ 是 HEAD^1^1 的简写,而 ^ 后面的数字表示后退一步到第几个父提交上,因为数字是1,所以 HEAD^^ 表示退一步到第一个父提交上,在退一步到第一个父提交上,这时与 HEAD~~ 的作用是相同的。
HEAD^2 就有些不同了,它表示后退一步到第二个父提交上,所以对照树形图是第二排的第二个节点。
~ 和 ^ 混合使用
看了上面的例子对于 ~ 和 ^ 的使用应该有些明白了,它俩其实可以组合使用的,比如想退到第5排、第2个节点上,也就是 ca4db4a 上,简单来看需要第一步到第一个父提交上,在退一步到第一个父提交上,然后退一步到第二个父提交上,最后退一步到第一个父提交上。
那么我们根据需求可以写成 HEAD^1^1^2^1,测试一下看看 hash 是否正确:
1 | albert@home-pc MINGW64 /d/gitstart (dev1) |
测试发现没有问题,其实还可以合并啊,我们知道1是可以省略的,所以可以简写成 HEAD^^^2^,另外多个 ^ 还可以写成 ~n 的形式,所以这个节点还可以表示成 HEAD~2^2^的样子,测试如下,结果是一样的。
1 | albert@home-pc MINGW64 /d/gitstart (dev1) |
关于 git reset 的一点思考
刚学习 git reset 的命令时一直认为是一个回退命令,其实学习一段时间之后发现,这个命令其实很符合它的名字,就是一个重置(reset)命令,通过 git reset 命令可以修改 HEAD 指向不同的提交,这个提交甚至都不必是当前分支上的某次提交,测试后发现,只要是版本库中合法提交都可以使用这个命令进行设置,相应的版本库的内容也会发生对应的变化,从这一点来看,它真的太强大了,它可以使你正在开发的 dev 分支瞬间变成 master 分支。
总结
HEAD~后面加数字表示后退的步数,每次后退都默认退到第一个父提交上,HEAD~2表示连退两步。HEAD^后面加数字表示只退一步,但是这一步后退到数字表示的父提交上,HEAD^2表示退一步到第二个父提交上。git在查看多分支提交记录时,日志的先后顺序不代表提交时间的先后顺序。git reset命令是一个重置HEAD的命令,可以指挥版本库指向任何一个合法提交。
俗话说:人不犯我,我不犯人;可俗话又说:先下手为强,后下手遭殃!
俗话说:宁为玉碎,不为瓦全;可俗话又说:留得青山在,不怕没柴烧!
…
其实只要你变成了那个成功的“俗话”,你说的就是金科玉律,警世哲理!2020-5-31 14:51:49
